

What Is A Discrete Function
A random variable (too called random quantity, aleatory variable, or stochastic variable) is a mathematical formalization of a quantity or object which depends on random events.[1] It is a mapping or a function from possible outcomes in a sample space to a measurable infinite, oftentimes the existent numbers.
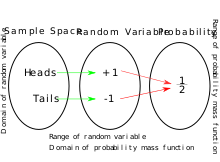
This graph shows how random variable is a part from all possible outcomes to existent values. It as well shows how random variable is used for defining probability mass functions.
Informally, randomness typically represents some central element of chance, such every bit in the roll of a dice; it may too correspond uncertainty, such as measurement error.[i] However, the interpretation of probability is philosophically complicated, and even in specific cases is not always straightforward. The purely mathematical analysis of random variables is contained of such interpretational difficulties, and can be based upon a rigorous axiomatic setup.
In the formal mathematical language of mensurate theory, a random variable is defined as a measurable function from a probability measure space (called the sample space) to a measurable space. This allows consideration of the pushforward measure, which is called the distribution of the random variable; the distribution is thus a probability measure on the set up of all possible values of the random variable. It is possible for two random variables to have identical distributions but to differ in pregnant ways; for instance, they may be independent.
It is common to consider the special cases of discrete random variables and absolutely continuous random variables, corresponding to whether a random variable is valued in a discrete gear up (such as a finite set) or in an interval of real numbers. There are other important possibilities, especially in the theory of stochastic processes, wherein it is natural to consider random sequences or random functions. Sometimes a random variable is taken to be automatically valued in the real numbers, with more general random quantities instead existence called random elements.
According to George Mackey, Pafnuty Chebyshev was the outset person "to recollect systematically in terms of random variables".[2]
Definition [edit]
A random variable is a measurable part from a ready of possible outcomes to a measurable infinite . The technical evident definition requires to exist a sample space of a probability triple (see the measure-theoretic definition). A random variable is often denoted past capital letter roman letters such as , , , .[3]








The probability that takes on a value in a measurable fix is written as


Standard example [edit]
In many cases, is real-valued, i.e. . In some contexts, the term random element (see extensions) is used to announce a random variable not of this form.

When the image (or range) of is countable, the random variable is called a discrete random variable [4] : 399 and its distribution is a discrete probability distribution, i.east. can be described past a probability mass function that assigns a probability to each value in the image of . If the epitome is uncountably infinite (commonly an interval) and so is called a continuous random variable.[5] [6] In the special case that it is absolutely continuous, its distribution can exist described past a probability density role, which assigns probabilities to intervals; in particular, each individual betoken must necessarily have probability zero for an admittedly continuous random variable. Not all continuous random variables are absolutely continuous,[seven] a mixture distribution is one such counterexample; such random variables cannot be described by a probability density or a probability mass role.
Any random variable tin can be described by its cumulative distribution function, which describes the probability that the random variable will be less than or equal to a certain value.
Extensions [edit]
The term "random variable" in statistics is traditionally express to the existent-valued example ( ). In this instance, the construction of the real numbers makes information technology possible to define quantities such equally the expected value and variance of a random variable, its cumulative distribution function, and the moments of its distribution.
However, the definition above is valid for any measurable infinite of values. Thus i can consider random elements of other sets , such every bit random boolean values, chiselled values, complex numbers, vectors, matrices, sequences, copse, sets, shapes, manifolds, and functions. Ane may and then specifically refer to a random variable of blazon , or an -valued random variable.
This more general concept of a random element is specially useful in disciplines such as graph theory, auto learning, tongue processing, and other fields in discrete mathematics and reckoner science, where 1 is oftentimes interested in modeling the random variation of non-numerical data structures. In some cases, it is even so user-friendly to represent each chemical element of , using one or more than real numbers. In this example, a random element may optionally be represented as a vector of real-valued random variables (all defined on the same underlying probability infinite , which allows the different random variables to covary). For example:
- A random discussion may be represented as a random integer that serves as an index into the vocabulary of possible words. Alternatively, it can be represented as a random indicator vector, whose length equals the size of the vocabulary, where the only values of positive probability are , , and the position of the 1 indicates the word.
- A random sentence of given length may be represented equally a vector of random words.
- A random graph on given vertices may be represented equally a matrix of random variables, whose values specify the adjacency matrix of the random graph.
- A random function may exist represented as a collection of random variables , giving the office's values at the diverse points in the part's domain. The are ordinary existent-valued random variables provided that the part is real-valued. For example, a stochastic process is a random function of time, a random vector is a random function of some alphabetize set such equally , and random field is a random role on whatever set (typically fourth dimension, space, or a discrete prepare).









Distribution functions [edit]
If a random variable defined on the probability space is given, we can inquire questions like "How likely is it that the value of is equal to 2?". This is the same as the probability of the event which is often written as or for short.




Recording all these probabilities of outputs of a random variable yields the probability distribution of . The probability distribution "forgets" about the particular probability space used to define and only records the probabilities of various output values of . Such a probability distribution, if is existent-valued, can always be captured by its cumulative distribution function

and sometimes as well using a probability density office, . In measure-theoretic terms, we utilise the random variable to "push button-forward" the measure on to a measure on . The underlying probability space is a technical device used to guarantee the beingness of random variables, sometimes to construct them, and to define notions such as correlation and dependence or independence based on a joint distribution of two or more random variables on the same probability space. In do, one often disposes of the space altogether and simply puts a measure on that assigns measure 1 to the whole existent line, i.e., 1 works with probability distributions instead of random variables. See the commodity on quantile functions for fuller evolution.



Examples [edit]
Detached random variable [edit]
In an experiment a person may be chosen at random, and ane random variable may exist the person'southward height. Mathematically, the random variable is interpreted as a function which maps the person to the person's height. Associated with the random variable is a probability distribution that allows the computation of the probability that the tiptop is in whatever subset of possible values, such as the probability that the height is between 180 and 190 cm, or the probability that the acme is either less than 150 or more than 200 cm.
Another random variable may exist the person's number of children; this is a discrete random variable with non-negative integer values. It allows the ciphering of probabilities for individual integer values – the probability mass office (PMF) – or for sets of values, including infinite sets. For example, the event of interest may be "an even number of children". For both finite and infinite event sets, their probabilities tin can be found past adding up the PMFs of the elements; that is, the probability of an even number of children is the space sum .

In examples such equally these, the sample space is frequently suppressed, since information technology is mathematically hard to describe, and the possible values of the random variables are then treated as a sample infinite. But when two random variables are measured on the aforementioned sample infinite of outcomes, such as the tiptop and number of children being computed on the same random persons, it is easier to runway their relationship if it is acknowledged that both height and number of children come up from the same random person, for example then that questions of whether such random variables are correlated or not can be posed.
If are countable sets of real numbers, and , then is a discrete distribution function. Here for 








Coin toss [edit]
The possible outcomes for one coin toss tin can exist described by the sample space . We can introduce a real-valued random variable that models a $i payoff for a successful bet on heads as follows:

![{\displaystyle Y(\omega )={\begin{cases}1,&{\text{if }}\omega ={\text{heads}},\\[6pt]0,&{\text{if }}\omega ={\text{tails}}.\end{cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2d200c2fc4177e66d480e649540dd91347a4b0be)
If the coin is a fair coin, Y has a probability mass part given by:

![{\displaystyle f_{Y}(y)={\begin{cases}{\tfrac {1}{2}},&{\text{if }}y=1,\\[6pt]{\tfrac {1}{2}},&{\text{if }}y=0,\end{cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/dc8892016fc9589bd86b7845a45d4882dddbbada)
Dice ringlet [edit]

If the sample space is the set of possible numbers rolled on two die, and the random variable of involvement is the sum S of the numbers on the ii dice, then Due south is a discrete random variable whose distribution is described by the probability mass function plotted as the height of picture columns hither.
A random variable can also be used to describe the process of rolling die and the possible outcomes. The most obvious representation for the 2-dice case is to take the set of pairs of numbers n 1 and n 2 from {1, 2, three, four, 5, six} (representing the numbers on the ii dice) as the sample space. The full number rolled (the sum of the numbers in each pair) is then a random variable Ten given past the part that maps the pair to the sum:

and (if the dice are fair) has a probability mass function f X given past:

Continuous random variable [edit]
Formally, a continuous random variable is a random variable whose cumulative distribution function is continuous everywhere.[8] In that location are no "gaps", which would stand for to numbers which have a finite probability of occurring. Instead, continuous random variables almost never take an verbal prescribed value c (formally, ) but there is a positive probability that its value will lie in particular intervals which can exist arbitrarily small. Continuous random variables commonly admit probability density functions (PDF), which narrate their CDF and probability measures; such distributions are as well called absolutely continuous; simply some continuous distributions are singular, or mixes of an absolutely continuous part and a singular role.

An example of a continuous random variable would exist one based on a spinner that tin choose a horizontal direction. Then the values taken by the random variable are directions. We could stand for these directions by N, West, East, Due south, Southeast, etc. Still, it is ordinarily more convenient to map the sample space to a random variable which takes values which are real numbers. This can be washed, for example, by mapping a direction to a bearing in degrees clockwise from North. The random variable then takes values which are real numbers from the interval [0, 360), with all parts of the range being "equally likely". In this case, Ten = the angle spun. Whatsoever real number has probability zero of being selected, but a positive probability can be assigned to any range of values. For example, the probability of choosing a number in [0, 180] is 1⁄2 . Instead of speaking of a probability mass part, nosotros say that the probability density of X is i/360. The probability of a subset of [0, 360) can be calculated past multiplying the measure of the set by 1/360. In general, the probability of a ready for a given continuous random variable can exist calculated by integrating the density over the given set.
More than formally, given any interval , a random variable is called a "continuous uniform random variable" (CURV) if the probability that it takes a value in a subinterval depends only on the length of the subinterval. This implies that the probability of falling in whatever subinterval is proportional to the length of the subinterval, that is, if a ≤ c ≤ d ≤ b , 1 has
![{\textstyle I=[a,b]=\{x\in \mathbb {R} :a\leq x\leq b\}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6a291b85e1772a1749a65c841769efcec2931376)
![{\displaystyle X_{I}\sim \operatorname {U} (I)=\operatorname {U} [a,b]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e796af5f27ecaec3fdf010383da162a4d29ea04d)

![{\displaystyle [c,d]\subseteq [a,b]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/32c4b90060cfad2522da60caeab608de43226f6e)
![{\displaystyle \Pr \left(X_{I}\in [c,d]\right)={\frac {d-c}{b-a}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a9a7688c1f4a293f87a100e4dcbfb86d5456009a)
where the final equality results from the unitarity axiom of probability. The probability density part of a CURV is given by the indicator function of its interval of back up normalized by the interval's length:
![{\displaystyle X\sim \operatorname {U} [a,b]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8a2c5c9c387a71f6b8511c8360740aed05476755)

Of particular interest is the uniform distribution on the unit interval . Samples of whatever desired probability distribution tin be generated by calculating the quantile part of on a randomly-generated number distributed uniformly on the unit interval. This exploits properties of cumulative distribution functions, which are a unifying framework for all random variables.
![[0,1]](https://wikimedia.org/api/rest_v1/media/math/render/svg/738f7d23bb2d9642bab520020873cccbef49768d)

Mixed type [edit]
A mixed random variable is a random variable whose cumulative distribution function is neither discrete nor everywhere-continuous.[8] It can be realized as a mixture of a discrete random variable and a continuous random variable; in which case the CDF will be the weighted average of the CDFs of the component variables.[8]
An example of a random variable of mixed type would be based on an experiment where a coin is flipped and the spinner is spun but if the upshot of the money toss is heads. If the consequence is tails, X = −1; otherwise X = the value of the spinner equally in the preceding case. At that place is a probability of one⁄2 that this random variable volition have the value −1. Other ranges of values would have half the probabilities of the terminal example.
Well-nigh generally, every probability distribution on the real line is a mixture of discrete part, singular part, and an absolutely continuous part; see Lebesgue'due south decomposition theorem § Refinement. The discrete function is full-bodied on a countable set, just this fix may be dense (like the set of all rational numbers).
Measure-theoretic definition [edit]
The most formal, axiomatic definition of a random variable involves measure theory. Continuous random variables are defined in terms of sets of numbers, along with functions that map such sets to probabilities. Considering of various difficulties (e.chiliad. the Banach–Tarski paradox) that arise if such sets are comparatively constrained, it is necessary to introduce what is termed a sigma-algebra to constrain the possible sets over which probabilities can be defined. Normally, a particular such sigma-algebra is used, the Borel σ-algebra, which allows for probabilities to exist defined over any sets that can be derived either directly from continuous intervals of numbers or by a finite or countably infinite number of unions and/or intersections of such intervals.[9]
The mensurate-theoretic definition is equally follows.
Let exist a probability infinite and a measurable space. So an -valued random variable is a measurable role , which ways that, for every subset , its preimage is -measurable; , where .[10] This definition enables united states to mensurate any subset in the target space by looking at its preimage, which by assumption is measurable.






In more than intuitive terms, a fellow member of is a possible issue, a member of is a measurable subset of possible outcomes, the role gives the probability of each such measurable subset, represents the set of values that the random variable can take (such as the set of real numbers), and a fellow member of is a "well-behaved" (measurable) subset of (those for which the probability may be adamant). The random variable is then a function from whatsoever outcome to a quantity, such that the outcomes leading to any useful subset of quantities for the random variable take a well-defined probability.

When is a topological space, and so the most common choice for the σ-algebra is the Borel σ-algebra , which is the σ-algebra generated by the collection of all open up sets in . In such case the -valued random variable is chosen an -valued random variable. Moreover, when the space is the real line , and so such a real-valued random variable is called simply a random variable.

Real-valued random variables [edit]
In this case the observation space is the set of existent numbers. Recall, is the probability space. For a real ascertainment space, the function is a existent-valued random variable if


This definition is a special case of the above because the fix generates the Borel σ-algebra on the set of real numbers, and it suffices to bank check measurability on any generating fix. Hither we can prove measurability on this generating ready by using the fact that .
![\{(-\infty ,r]:r\in \mathbb {R} \}](https://wikimedia.org/api/rest_v1/media/math/render/svg/70d40dbc8dd41bbe90d6242042f72e62bafea8f9)
![\{\omega :X(\omega )\leq r\}=X^{-1}((-\infty ,r])](https://wikimedia.org/api/rest_v1/media/math/render/svg/967b79350e615a40cee0dd0102fee55bfb3c5d3d)
Moments [edit]
The probability distribution of a random variable is often characterised by a small number of parameters, which also have a practical interpretation. For example, it is oftentimes enough to know what its "average value" is. This is captured past the mathematical concept of expected value of a random variable, denoted , and also called the first moment. In general, is non equal to . One time the "average value" is known, ane could and then inquire how far from this boilerplate value the values of typically are, a question that is answered by the variance and standard divergence of a random variable. can be viewed intuitively as an average obtained from an infinite population, the members of which are item evaluations of .
![\operatorname {E} [X]](https://wikimedia.org/api/rest_v1/media/math/render/svg/44dd294aa33c0865f58e2b1bdaf44ebe911dbf93)
![{\displaystyle \operatorname {E} [f(X)]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c407e0dfff7f7d09b8a81f9ccc2f078bffa783ea)
![{\displaystyle f(\operatorname {E} [X])}](https://wikimedia.org/api/rest_v1/media/math/render/svg/358c53d63b891b58814383d8beba46f69695632f)
Mathematically, this is known as the (generalised) problem of moments: for a given form of random variables , find a drove of functions such that the expectation values fully characterise the distribution of the random variable .

![{\displaystyle \operatorname {E} [f_{i}(X)]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0e4e5f5f0c5d751d4d1bf63dea54ff9765683a53)
Moments can only be defined for real-valued functions of random variables (or complex-valued, etc.). If the random variable is itself existent-valued, then moments of the variable itself can be taken, which are equivalent to moments of the identity function of the random variable. However, even for non-real-valued random variables, moments can exist taken of real-valued functions of those variables. For instance, for a categorical random variable X that can have on the nominal values "red", "blue" or "green", the real-valued function can be constructed; this uses the Iverson bracket, and has the value ane if has the value "green", 0 otherwise. So, the expected value and other moments of this function tin can be adamant.

![[X={\text{green}}]](https://wikimedia.org/api/rest_v1/media/math/render/svg/e41a3122d8561d29d90be48b6c1fb0f94d8e2a81)
Functions of random variables [edit]
A new random variable Y can be defined by applying a real Borel measurable part to the outcomes of a real-valued random variable . That is, . The cumulative distribution part of is and so



If office is invertible (i.e., exists, where is 's inverse function) and is either increasing or decreasing, then the previous relation tin be extended to obtain




With the same hypotheses of invertibility of , bold also differentiability, the relation betwixt the probability density functions can be found past differentiating both sides of the above expression with respect to , in society to obtain[8]


If there is no invertibility of just each admits at almost a countable number of roots (i.e., a finite, or countably infinite, number of such that ) then the previous relation between the probability density functions can be generalized with



where , according to the inverse function theorem. The formulas for densities practice not demand to exist increasing.

In the measure-theoretic, axiomatic approach to probability, if a random variable on and a Borel measurable function , then is also a random variable on , since the composition of measurable functions is likewise measurable. (However, this is not necessarily truthful if is Lebesgue measurable.[ commendation needed ]) The same process that allowed one to become from a probability space to can exist used to obtain the distribution of .


Example i [edit]
Allow exist a real-valued, continuous random variable and let .


If 


If , and so


so

Example ii [edit]
Suppose is a random variable with a cumulative distribution

where is a fixed parameter. Consider the random variable And then,



The last expression tin can exist calculated in terms of the cumulative distribution of so

![{\displaystyle {\begin{aligned}F_{Y}(y)&=1-F_{X}(-\log(e^{y}-1))\\[5pt]&=1-{\frac {1}{(1+e^{\log(e^{y}-1)})^{\theta }}}\\[5pt]&=1-{\frac {1}{(1+e^{y}-1)^{\theta }}}\\[5pt]&=1-e^{-y\theta }.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f4909911022c68c07e09a3cd4722e9c60b62a4f3)
which is the cumulative distribution function (CDF) of an exponential distribution.
Example 3 [edit]
Suppose is a random variable with a standard normal distribution, whose density is

Consider the random variable We can find the density using the above formula for a change of variables:


In this example the change is not monotonic, because every value of has two corresponding values of (one positive and negative). All the same, because of symmetry, both halves will transform identically, i.e.,

The changed transformation is

and its derivative is

Then,

This is a chi-squared distribution with one degree of freedom.
Example 4 [edit]
Suppose is a random variable with a normal distribution, whose density is

Consider the random variable We can notice the density using the above formula for a change of variables:
In this case the modify is not monotonic, because every value of has two respective values of (one positive and negative). Differently from the previous example, in this case however, there is no symmetry and we take to compute the ii distinct terms:

The inverse transformation is

and its derivative is

Then,

This is a noncentral chi-squared distribution with 1 caste of freedom.
Some properties [edit]
- The probability distribution of the sum of two independent random variables is the convolution of each of their distributions.
- Probability distributions are not a vector space—they are non closed under linear combinations, equally these do not preserve non-negativity or total integral 1—only they are closed under convex combination, thus forming a convex subset of the infinite of functions (or measures).
Equivalence of random variables [edit]
There are several different senses in which random variables can be considered to be equivalent. Two random variables can be equal, equal almost surely, or equal in distribution.
In increasing club of forcefulness, the precise definition of these notions of equivalence is given below.
Equality in distribution [edit]
If the sample space is a subset of the existent line, random variables Ten and Y are equal in distribution (denoted ) if they have the same distribution functions:


To be equal in distribution, random variables need non be defined on the aforementioned probability space. Two random variables having equal moment generating functions take the same distribution. This provides, for example, a useful method of checking equality of certain functions of independent, identically distributed (IID) random variables. Withal, the moment generating role exists simply for distributions that have a defined Laplace transform.
Virtually sure equality [edit]
Two random variables X and Y are equal virtually surely (denoted ) if, and only if, the probability that they are unlike is zero:


For all practical purposes in probability theory, this notion of equivalence is as stiff as actual equality. Information technology is associated to the following distance:

where "ess sup" represents the essential supremum in the sense of measure theory.
Equality [edit]
Finally, the two random variables 10 and Y are equal if they are equal equally functions on their measurable space:

This notion is typically the least useful in probability theory considering in practice and in theory, the underlying measure infinite of the experiment is rarely explicitly characterized or even characterizable.
Convergence [edit]
A significant theme in mathematical statistics consists of obtaining convergence results for certain sequences of random variables; for instance the law of large numbers and the cardinal limit theorem.
There are various senses in which a sequence of random variables can converge to a random variable . These are explained in the article on convergence of random variables.

See besides [edit]
- Aleatoricism
- Algebra of random variables
- Result (probability theory)
- Multivariate random variable
- Pairwise independent random variables
- Appreciable variable
- Random element
- Random function
- Random measure
- Random number generator produces a random value
- Random variate
- Random vector
- Randomness
- Stochastic process
- Relationships amidst probability distributions
References [edit]
Inline citations [edit]
- ^ a b Blitzstein, Joe; Hwang, Jessica (2014). Introduction to Probability. CRC Printing. ISBN9781466575592.
- ^ George Mackey (July 1980). "Harmonic assay every bit the exploitation of symmetry - a historical survey". Bulletin of the American Mathematical Gild. New Series. 3 (ane).
- ^ "Random Variables". www.mathsisfun.com . Retrieved 2020-08-21 .
- ^ Yates, Daniel Due south.; Moore, David S; Starnes, Daren S. (2003). The Exercise of Statistics (2d ed.). New York: Freeman. ISBN978-0-7167-4773-4. Archived from the original on 2005-02-09.
- ^ "Random Variables". world wide web.stat.yale.edu . Retrieved 2020-08-21 .
- ^ Dekking, Frederik Michel; Kraaikamp, Cornelis; Lopuhaä, Hendrik Paul; Meester, Ludolf Erwin (2005). "A Modern Introduction to Probability and Statistics". Springer Texts in Statistics. doi:10.1007/1-84628-168-7. ISBN978-ane-85233-896-one. ISSN 1431-875X.
- ^ L. Castañeda; V. Arunachalam & Due south. Dharmaraja (2012). Introduction to Probability and Stochastic Processes with Applications. Wiley. p. 67. ISBN9781118344941.
- ^ a b c d Bertsekas, Dimitri P. (2002). Introduction to Probability. Tsitsiklis, John N., Τσιτσικλής, Γιάννης Ν. Belmont, Mass.: Athena Scientific. ISBN188652940X. OCLC 51441829.
- ^ Steigerwald, Douglas Grand. "Economics 245A – Introduction to Measure Theory" (PDF). University of California, Santa Barbara. Retrieved Apr 26, 2013.
- ^ Fristedt & Gray (1996, folio 11)
Literature [edit]
- Fristedt, Bert; Greyness, Lawrence (1996). A modern approach to probability theory. Boston: Birkhäuser. ISBN3-7643-3807-5.
- Kallenberg, Olav (1986). Random Measures (fourth ed.). Berlin: Akademie Verlag. ISBN0-12-394960-2. MR 0854102.
- Kallenberg, Olav (2001). Foundations of Mod Probability (2d ed.). Berlin: Springer Verlag. ISBN0-387-95313-two.
- Papoulis, Athanasios (1965). Probability, Random Variables, and Stochastic Processes (ninth ed.). Tokyo: McGraw–Hill. ISBN0-07-119981-0.
External links [edit]
- "Random variable", Encyclopedia of Mathematics, EMS Press, 2001 [1994]
- Zukerman, Moshe (2014), Introduction to Queueing Theory and Stochastic Teletraffic Models (PDF), arXiv:1307.2968
- Zukerman, Moshe (2014), Basic Probability Topics (PDF)

What Is A Discrete Function,
Source: https://en.wikipedia.org/wiki/Random_variable
Posted by: cliffordponeely.blogspot.com
0 Response to "What Is A Discrete Function"
Post a Comment